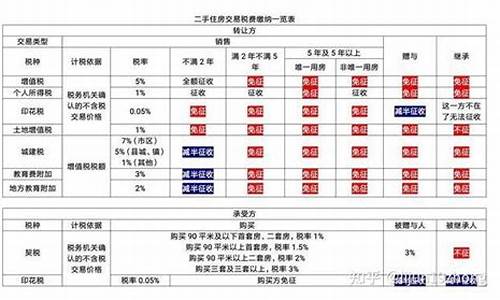
python爬取二手房信息保存到MySQL里面_python爬取二手房信息
1.python最多可以多少线程(python线程数量)
2.Python爬虫如何写?
3.一篇文章带你深度解析Python线程和进程
4.基于python的毕业设计题目(关于python的毕设题目)

对房屋有更深层面的认知
通过这段代码可以看一下这些房子分布在哪里。结论见代码下截图,如果你对北京熟悉,可以看到,这些房子主要分布在5环外,部分在顺义、昌平、门头沟等地。
通过对装修状态做价格分布图可以看到,精装修的集中在400±100万左右,简装稍微便宜一丢丢,毛坯房二手很少,其他形式的很多,价格集中在300-500万左右,对装修状态进行楼房形式的拆解后做箱型图如上,得到结论是板楼、塔楼、板楼塔楼结合是最多的,不论是精装简装还是其他信息不明的装修状态的。对建筑形式连同装修状态和价格关系可以看到,不论什么类型的建筑形式,都存在精装修、简装修、毛坯。板楼价格横跨100万-1000万之间,集中在300-600万之间,板楼塔楼结合的价格集中在350万-700万之间,塔楼集中在380-700万之间。初步结论,如果能搞到300万以上,精装修的板楼或塔楼随便选。
python最多可以多少线程(python线程数量)
导读:很多朋友问到关于python中1009等于多少的相关问题,本文首席CTO笔记就来为大家做个详细解答,供大家参考,希望对大家有所帮助!一起来看看吧!
求大于1000最小的10个素数的和python2.7?大于1000的最小10个素数是
1009,1013,1019,1021,1031,1033,1039,1049,1051,1061
他们的和是10326
python中123//100等于多少python中123//100等于1。python中123和100是整型数据类型,//是除法,2个整型数据类型相除,结果只能只能是整型数据类型,123/100取百位等于1,所以python中123//100等于1。
python中计算2的100次方中有多少个9两个。
2的一百次方等于:1267650600228229401496703205376
这个数值是非常大的,可以用以下例子将这个数值“实体化”:例如存在一张可以充分折叠的纸厚度为0.1毫米,其他厚度忽略不计,对半折一次,则厚度是0.2mm,再对折一次,是0.4mm由此类推,对折n次,那么纸的厚度是:(2^n)×0.1mm
这个厚度的增长将呈指数增长的趋势,那么折了100次后,厚度达到1268万亿亿千米,若把这个单位换算成“光年”,那么其长度达到“134亿光年”,而宇宙大爆炸至今的全部时间仅仅才137亿年。
Python中的0x10010是十进制的多少
十进制。
平时使用的数字是十进制,逢10进1,而计算机用的是二进制,此外,有时你还会遇到八进制,十六进制,其实只要掌握好方法,这些进制的理解就不难,相互之间的转换也并不复杂。
使用int函数可以将二进制,八进制,十六进制的数值转成十进制数值,而且字符串的开头可以不携带进制的标识,如果你喜欢使用,也可以写成int,并没有函数可以实现直接将八进制或十六进制数转成二进制,因此需要借用int函数先将八进制的数转成十进制,然后使用bin函数将十进制数转成二进制。
python中一千三百六十一怎么写Python中文转数字(整数,小数,纯数字通用版)原创
2018-11-1013:14:26
1点赞
Sailist
码龄6年
关注
文章知识点与官方知识档案匹配
Python入门技能树首页概览
211446人正在系统学习中
打开CSDNAPP,看更多技术内容
python转换整数_在Python中将数字转换为整数列表_出门耍的博客-CSDN...
作为Python中数据处理的一部分,有时我们可能需要将给定的数字转换为包含该数字的列表。在本文中,我们将介绍实现这一目标的方法。具有列表理解在下面的方法中,我们将str函数应用于给定的数字,然后通过恒等函数转换为整数。最后,我们将结果...
继续访问
python实现将字符串转换为整数_修炼之路的博客_python将字符...
输出:-2147483648解释:数字“-91283472332”超过32位有符号整数范围。因此返回INT_MIN(?231)。代码实现正则表达式可以利用python自带的re库,来实现这个功能importreclassSolution1(object):defmyAtoi(self,s):INT_...
继续访问
Python基础语法数据类型转换转字符串转整数转小数
转换数据类型的函数一共有3种:str()、int()和float()函数说明注意str()将其他数据类型转成字符串也可以用引号转换int()将其他数据类型转成整数1.文字类和小数类字符串,无法转成整数2.浮点数转成整数:抹零取整(非四舍五入)float()将其他数据类型转成浮点数文字类数据类型无法转成小数代码:...
继续访问
Python的时间线
自从20世纪90年代初Python语言诞生至今,它已被逐渐广泛应用于系统管理任务的处理和Web编程。Python的创始人为荷兰人吉多·范罗苏姆(GuidovanRossum)。1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,作为ABC语言的一种继承。之所以选中Python(大蟒蛇的意思)作为该编程语言的名字,是取自英国20世纪70年代首播的电视喜剧《蒙提.派森的飞行马戏团》(MontyPython’sFlyingCircus)。ABC
继续访问
字符串转换整数python_Python将字符串转换为整数_culing2941的博客-CSD...
在本教程中,您将看到在python中将字符串转换为整数的两种方法。Asweknowwedon’thetodeclarethedatatypewhiledeclaringvariablesinPython.Aspythonwillassignadatatypeaccordingtoourdatastoredinth...
继续访问
Python中文数字转阿拉伯数字_Legend_35332332的博客_python中文...
defnumber_C2E(ChineseNumber):"""中文数字转整形"""map=dict(〇=0,一=1,二=2,三=3,四=4,五=5,六=6,七=7,八=8,九=9,十=10)size=len(ChineseNumber)ifsize==0:return0ifsi...
继续访问
python带e的科学计数法转普通数字
例如,现有浮点数0.00001623,在python中会默认用科学计数法1.623e-05表示。如果只是希望通过print方式显示的时候是普通数字的话,那么格式化下即可。
继续访问
热门推荐python中,如何将字符串转换为数字(将数字转换为整型),字符串的10转换为整型的10,10.5转换为10...
说明:在实际的应用过程中,有的时候可能会遇到字符串的10,需要将字符串的10转换为数字的10在此记录下,通过int函数转换的过程。操作过程:1.将字符串转换为整型的10str1="10"#将一个字符串的10赋给变量str1type(str1)class'str'...
继续访问
Python中文数字转数字(阿拉伯)__yuki_的博客_python...
Python中文数字转数字(阿拉伯)直接上代码:方法一:common_used_numerals_tmp={'零':0,'一':1,'二':2,'两':2,'三':3,'四':4,'五':5,'六':6,'七':7,'八':8,'九':9,'十':10,'百':100,'千':1000,...
继续访问
python字符串转换成整数_在Python中将字符串转换为整数的方法_weixin...
在本文中,我们将向你展示如何将Python字符串转换为整数,可在Linux操作平台上进行。Python中的所有数据类型(包括整数和字符串)都是对象,通常在编写Python代码时,你需要将一种数据类型转换为另一种数据类型,例如,要对表示为字符串的数字进...
继续访问
最新发布python——数字类型和转换
Python数字数据类型用于存储数值。数字类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间。可以通过-通常被称为是整型或整数,有正或负整数,不带小数点。Python3整型是没有限制大小的,可以当作long类型使用,所以Python3没有Python2的long类型。布尔(bool)是整型的子类型。
继续访问
(一行代码)Python科学计数法转普通数值
Python科学计数法转普通数值小记小记核心主题:通过‘%f’来将科学计数法转为普通计数目标:将数值以普通数字形式写入到ASCII编码文件中问题:1、数值来源于外部,获取到的就是科学计数法2、懒,只想写一行代码。不想用字符串再做正则匹配,再重新补全数值解决:1、获取到的数据如下[(-0.00010158695658901706,-3.
继续访问
python中文数字对照表_2019-02-17Python中文数字转阿拉伯数字
sum=0#把中文数字转换为整数table=str.maketrans('一二三四五六七八九','123456789')#遇到十,百,千这些之前temp=1forchrinchi:#print(chr)ifchr=="十":sum+=(temp*10)...
继续访问
在Python中如何将字符串转换为整数_IT娜娜的博客_python字...
类似于内置的str()方法,Python语言中有一个很好用的int()方法,可以将字符串对象作为参数,并返回一个整数。用法示例:#Hereageisastringobjectage="18"print(age)#Convertingastringtoaninteger...
继续访问
Python实现单位(亿、万)转数字
文章目录背景测试样例转化测试结果结束语背景近日遇到一个需求,要将"xx亿xx万"、"xx亿"、"xx万"转为数字本来想着CSDN上肯定有,就懒得造轮子,正好找到了一个,链接如下:python|数值单位(个十百千万亿)转换成数字但是发现竟然是尊贵的VIP文章,本着"拒绝哄抬X价,从我做起"的原则,一气之下就花了几分钟写出来测试样例valueStrList=['15亿3710万','15.04亿','4762.75万','771.56']转化defstr2value(v
继续访问
Python单位(亿、万)转数字
需求背景今天在爬取长沙链接二手房数据的时候,需要将房屋总价和单价转换为数字进行存储python功能代码:实现str转int,要求:包含'亿'=1e8,包含'万'=1e4。功能代码如下:defstr2value(valueStr):valueStr=str(valueStr)idxOfYi=valueStr.find('亿')idxOfWan=valueStr.find('万')ifidxOfYi!=-1andi...
继续访问
python大写金额转换为数字的简单算法
python大写金额转换为数字的简单算法背景:项目中遇到的人为填写的大写金额需要转换为数字。目前只支持整元未考虑角分的情况。如:一亿三千万--13000000十万--100000一百九十万--1900000一万零一十--10010拾亿零叁佰肆拾柒万零贰拾捌--1003470028实现逻辑:1.根据数字的读取规则,个十百千万亿,大于10的为单位,等于10的情况要分单位和
继续访问
python强制类型转换为数值型_python数据类型的强制转换
数据类型的强制转换如果要将一个数据转换成另一个数据类型,只需要将其放入相应类型的函数中去。Number类型的数据转换强制转换为int可以转换的数据类型int整型float浮点型bool布尔型str字符串(整型)数据转换#整型(整型转换是原封不动的)print(int(10))#浮点型(浮点型转成整型按照退一法)print(int(10.999))#布尔型(布尔型只有两种值,转换成为整...
继续访问
python数据类型转换、将数值转换为以万为单位的数_少儿编程:Python系列25——数据
结语:以上就是首席CTO笔记为大家整理的关于python中1009等于多少的全部内容了,感谢您花时间阅读本站内容,希望对您有所帮助,更多关于python中1009等于多少的相关内容别忘了在本站进行查找喔。
Python爬虫如何写?
导读:很多朋友问到关于python最多可以多少线程的相关问题,本文首席CTO笔记就来为大家做个详细解答,供大家参考,希望对大家有所帮助!一起来看看吧!
Python多线程总结在实际处理数据时,因系统内存有限,我们不可能一次把所有数据都导出进行操作,所以需要批量导出依次操作。为了加快运行,我们会用多线程的方法进行数据处理,以下为我总结的多线程批量处理数据的模板:
主要分为三大部分:
共分4部分对多线程的内容进行总结。
先为大家介绍线程的相关概念:
在飞车程序中,如果没有多线程,我们就不能一边听歌一边玩飞车,听歌与玩游戏不能并行;在使用多线程后,我们就可以在玩游戏的同时听背景音乐。在这个例子中启动飞车程序就是一个进程,玩游戏和听音乐是两个线程。
Python提供了threading模块来实现多线程:
因为新建线程系统需要分配、终止线程系统需要回收,所以如果可以重用线程,则可以减去新建/终止的开销以提升性能。同时,使用线程池的语法比自己新建线程执行线程更加简洁。
Python为我们提供了ThreadPoolExecutor来实现线程池,此线程池默认子线程守护。它的适应场景为突发性大量请求或需要大量线程完成任务,但实际任务处理时间较短。
其中max_workers为线程池中的线程个数,常用的遍历方法有map和submit+as_completed。根据业务场景的不同,若我们需要输出结果按遍历顺序返回,我们就用map方法,若想谁先完成就返回谁,我们就用submit+as_complete方法。
我们把一个时间段内只允许一个线程使用的称为临界,对临界的访问,必须互斥的进行。互斥,也称间接制约关系。线程互斥指当一个线程访问某临界时,另一个想要访问该临界的线程必须等待。当前访问临界的线程访问结束,释放该之后,另一个线程才能去访问临界。锁的功能就是实现线程互斥。
我把线程互斥比作厕所包间上大号的过程,因为包间里只有一个坑,所以只允许一个人进行大号。当第一个人要上厕所时,会将门上上锁,这时如果第二个人也想大号,那就必须等第一个人上完,将锁解开后才能进行,在这期间第二个人就只能在门外等着。这个过程与代码中使用锁的原理如出一辙,这里的坑就是临界。Python的threading模块引入了锁。threading模块提供了Lock类,它有如下方法加锁和释放锁:
我们会发现这个程序只会打印“第一道锁”,而且程序既没有终止,也没有继续运行。这是因为Lock锁在同一线程内第一次加锁之后还没有释放时,就进行了第二次acquire请求,导致无法执行release,所以锁永远无法释放,这就是死锁。如果我们使用RLock就能正常运行,不会发生死锁的状态。
在主线程中定义Lock锁,然后上锁,再创建一个子线程t运行main函数释放锁,结果正常输出,说明主线程上的锁,可由子线程解锁。
如果把上面的锁改为RLock则报错。在实际中设计程序时,我们会将每个功能分别封装成一个函数,每个函数中都可能会有临界区域,所以就需要用到RLock。
一句话总结就是Lock不能套娃,RLock可以套娃;Lock可以由其他线程中的锁进行操作,RLock只能由本线程进行操作。
python之多线程进程的概念:以一个整体的形式暴露给操作系统管理,里面包含各种的调用。对各种管理的集合就可以称为进程。
线程的概念:是操作系统能够进行运算调度的最小单位。本质上就是一串指令的集合。
进程和线程的区别:
1、线程共享内存空间,进程有独立的内存空间。
2、线程启动速度快,进程启动速度慢。注意:二者的运行速度是无法比较的。
3、线程是执行的指令集,进程是的集合
4、两个子进程之间数据不共享,完全独立。同一个进程下的线程共享同一份数据。
5、创建新的线程很简单,创建新的进程需要对他的父进程进行一次克隆。
6、一个线程可以操作(控制)同一进程里的其他线程,但是进程只能操作子进程
7、同一个进程的线程可以直接交流,两个进程想要通信,必须通过一个中间代理来实现。
8、对于线程的修改,可能会影响到其他线程的行为。但是对于父进程的修改不会影响到子进程。
第一个程序,使用循环来创建线程,但是这个程序中一共有51个线程,我们创建了50个线程,但是还有一个程序本身的线程,是主线程。这51个线程是并行的。注意:这个程序中是主线程启动了子线程。
相比上个程序,这个程序多了一步计算时间,但是我们观察结果会发现,程序显示的执行时间只有0.007秒,这是因为最后一个print函数它存在于主线程,而整个程序主线程和所有子线程是并行的,那么可想而知,在子线程还没有执行完毕的时候print函数就已经执行了,总的来说,这个时间只是执行了一个线程也就是主线程所用的时间。
接下来这个程序,吸取了上面这个程序的缺点,创建了一个列表,把所有的线程实例都存进去,然后使用一个for循环依次对线程实例调用join方法,这样就可以使得主线程等待所创建的所有子线程执行完毕才能往下走。注意实验结果:和两个线程的结果都是两秒多一点
注意观察实验结果,并没有执行打印taskhasdone,并且程序执行时间极其短。
这是因为在主线程启动子线程前把子线程设置为守护线程。
只要主线程执行完毕,不管子线程是否执行完毕,就结束。但是会等待非守护线程执行完毕
主线程退出,守护线程全部强制退出。皇帝死了,仆人也跟着殉葬
应用的场景:socket-server
注意:gil只是为了减低程序开发复杂度。但是在2.几的版本上,需要加用户态的锁(gil的缺陷)而在3点几的版本上,加锁不加锁都一样。
下面这个程序是一个典型的生产者消费者模型。
生产者消费者模型是经典的在开发架构中使用的模型
运维中的集群就是生产者消费者模型,生活中很多都是
那么,多线程的使用场景是什么?
python中的多线程实质上是对上下文的不断切换,可以说是的多线程。而我们知道,io操作不占用cpu,计算占用cpu,那么python的多线程适合io操作密集的任务,比如socket-server,那么cpu密集型的任务,python怎么处理?python可以折中的利用计算机的多核:启动八个进程,每个进程有一个线程。这样就可以利用多进程解决多核问题。
python多线程
有很多的场景中的事情是同时进行的,比如开车的时候,手和脚共同来驾驶汽车,再比如唱歌跳舞也是同时进行的
结果:
_thread threading(推荐使用)结果:
threading.enumerate()可查看当前正在运行的线程
结果:
结果:
结果:
结果:出现竞争导致计算结果不正确
(1)当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
(2)线程同步能够保证多个线程安全访问,最简单的同步机制是引入互斥锁
(3)互斥锁为引入一个状态:锁定/非锁定
(4)某个线程要更爱共享数据时,先将其锁定,此时的状态为"锁定",其他线程不能更改;直到该线程释放,将状态变为"非锁定"
(5)互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性
结果:计算正确
结果:卡住了
在线程间共享多个的时候,如果两个线程分别战友一部分且同时等待对方,就会造成死锁
(1)程序设计时避免(银行家算法)
(2)添加超时时间
一篇文章带你深度解析Python线程和进程使用Python中的线程模块,能够同时运行程序的不同部分,并简化设计。如果你已经入门Python,并且想用线程来提升程序运行速度的话,希望这篇教程会对你有所帮助。
线程与进程
什么是进程
进程是系统进行分配和调度的一个独立单位进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
什么是线程
CPU调度和分派的基本单位线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统,只拥有一点在运行中必不可少的(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部。线程间通信主要通过共享内存,上下文切换很快,开销较少,但相比进程不够稳定容易丢失数据。
进程与线程的关系图
线程与进程的区别:
进程
现实生活中,有很多的场景中的事情是同时进行的,比如开车的时候手和脚共同来驾驶汽车,比如唱歌跳舞也是同时进行的,再比如边吃饭边打电话;试想如果我们吃饭的时候有一个领导来电,我们肯定是立刻就接听了。但是如果你吃完饭再接听或者回电话,很可能会被开除。
注意:
多任务的概念
什么叫多任务呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒,这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。其实就是CPU执行速度太快啦!以至于我们感受不到在轮流调度。
并行与并发
并行(Parallelism)
并行:指两个或两个以上(或线程)在同一时刻发生,是真正意义上的不同或线程在同一时刻,在不同CPU呢上(多核),同时执行。
特点
并发(Concurrency)
指一个物理CPU(也可以多个物理CPU)在若干道程序(或线程)之间多路复用,并发性是对有限物理强制行使多用户共享以提高效率。
特点
multiprocess.Process模块
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
语法:Process([group[,target[,name[,args[,kwargs]]]]])
由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)。
注意:1.必须使用关键字方式来指定参数;2.args指定的为传给target函数的位置参数,是一个元祖形式,必须有逗号。
参数介绍:
group:参数未使用,默认值为None。
target:表示调用对象,即子进程要执行的任务。
args:表示调用的位置参数元祖。
kwargs:表示调用对象的字典。如kwargs={'name':Jack,'age':18}。
name:子进程名称。
代码:
除了上面这些开启进程的方法之外,还有一种以继承Process的方式开启进程的方式:
通过上面的研究,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的运行没有顺序,一旦开启也不受我们控制。尽管并发编程让我们能更加充分的利用IO,但是也给我们带来了新的问题。
当多个进程使用同一份数据的时候,就会引发数据安全或顺序混乱问题,我们可以考虑加锁,我们以模拟抢票为例,来看看数据安全的重要性。
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改。加锁牺牲了速度,但是却保证了数据的安全。
因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。
mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。队列和管道都是将数据存放于内存中队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来,我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性(后续扩展该内容)。
线程
Python的threading模块
Python供了几个用于多线程编程的模块,包括thread,threading和Queue等。thread和threading模块允许程序员创建和管理线程。thread模块供了基本的线程和锁的支持,而threading供了更高级别,功能更强的线程管理的功能。Queue模块允许用户创建一个可以用于多个线程之间共享数据的队列数据结构。
python创建和执行线程
创建线程代码
1.创建方法一:
2.创建方法二:
进程和线程都是实现多任务的一种方式,例如:在同一台计算机上能同时运行多个QQ(进程),一个QQ可以打开多个聊天窗口(线程)。共享:进程不能共享,而线程共享所在进程的地址空间和其他,同时,线程有自己的栈和栈指针。所以在一个进程内的所有线程共享全局变量,但多线程对全局变量的更改会导致变量值得混乱。
代码演示:
得到的结果是:
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行(其中的JPython就没有GIL)。
那么CPython实现中的GIL又是什么呢?GIL全称GlobalInterpreterLock为了避免误导,我们还是来看一下官方给出的解释:
主要意思为:
因此,解释器实际上被一个全局解释器锁保护着,它确保任何时候都只有一个Python线程执行。在多线程环境中,Python虚拟机按以下方式执行:
由于GIL的存在,Python的多线程不能称之为严格的多线程。因为多线程下每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行。
由于GIL的存在,即使是多线程,事实上同一时刻只能保证一个线程在运行,既然这样多线程的运行效率不就和单线程一样了吗,那为什么还要使用多线程呢?
由于以前的电脑基本都是单核CPU,多线程和单线程几乎看不出差别,可是由于计算机的迅速发展,现在的电脑几乎都是多核CPU了,最少也是两个核心数的,这时差别就出来了:通过之前的案例我们已经知道,即使在多核CPU中,多线程同一时刻也只有一个线程在运行,这样不仅不能利用多核CPU的优势,反而由于每个线程在多个CPU上是交替执行的,导致在不同CPU上切换时造成的浪费,反而会更慢。即原因是一个进程只存在一把gil锁,当在执行多个线程时,内部会争抢gil锁,这会造成当某一个线程没有抢到锁的时候会让cpu等待,进而不能合理利用多核cpu。
但是在使用多线程抓取网页内容时,遇到IO阻塞时,正在执行的线程会暂时释放GIL锁,这时其它线程会利用这个空隙时间,执行自己的代码,因此多线程抓取比单线程抓取性能要好,所以我们还是要使用多线程的。
GIL对多线程Python程序的影响
程序的性能受到计算密集型(CPU)的程序限制和I/O密集型的程序限制影响,那什么是计算密集型和I/O密集型程序呢?
计算密集型:要进行大量的数值计算,例如进行上亿的数字计算、计算圆周率、对进行解码等等。这种计算密集型任务虽然也可以用多任务完成,但是花费的主要时间在任务切换的时间,此时CPU执行任务的效率比较低。
IO密集型:涉及到网络请求(time.sleep())、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。
当然为了避免GIL对我们程序产生影响,我们也可以使用,线程锁。
LockRLock
常用的共享锁机制:有Lock、RLock、Semphore、Condition等,简单给大家分享下Lock和RLock。
Lock
特点就是执行速度慢,但是保证了数据的安全性
RLock
使用锁代码操作不当就会产生死锁的情况。
什么是死锁
死锁:当线程A持有独占锁a,并尝试去获取独占锁b的同时,线程B持有独占锁b,并尝试获取独占锁a的情况下,就会发生AB两个线程由于互相持有对方需要的锁,而发生的阻塞现象,我们称为死锁。即死锁是指多个进程因竞争而造成的一种僵局,若无外力作用,这些进程都将无法向前推进。
所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定的合理分配算法,避免进程永久占据系统。
死锁代码
python线程间通信
如果各个线程之间各干各的,确实不需要通信,这样的代码也十分的简单。但这一般是不可能的,至少线程要和主线程进行通信,不然计算结果等内容无法取回。而实际情况中要复杂的多,多个线程间需要交换数据,才能得到正确的执行结果。
python中Queue是消息队列,提供线程间通信机制,python3中重名为为queue,queue模块块下提供了几个阻塞队列,这些队列主要用于实现线程通信。
在queue模块下主要提供了三个类,分别代表三种队列,它们的主要区别就在于进队列、出队列的不同。
简单代码演示
此时代码会阻塞,因为queue中内容已满,此时可以在第四个queue.put('苹果')后面添加timeout,则成为queue.put('苹果',timeout=1)如果等待1秒钟仍然是满的就会抛出异常,可以捕获异常。
同理如果队列是空的,无法获取到内容默认也会阻塞,如果不阻塞可以使用queue.get_nowait()。
在掌握了Queue阻塞队列的特性之后,在下面程序中就可以利用Queue来实现线程通信了。
下面演示一个生产者和一个消费者,当然都可以多个
使用queue模块,可在线程间进行通信,并保证了线程安全。
协程
协程,又称微线程,纤程。英文名Coroutine。
协程是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的)。为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机,我们可以把一个协程切换到另一个协程。只要这个过程中保存或恢复CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定。
在实现多任务时,线程切换从系统层面远不止保存和恢复CPU上下文这么简单。操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
greenlet与gevent
为了更好使用协程来完成多任务,除了使用原生的yield完成模拟协程的工作,其实python还有的greenlet模块和gevent模块,使实现协程变的更加简单高效。
greenlet虽说实现了协程,但需要我们手工切换,太麻烦了,gevent是比greenlet更强大的并且能够自动切换任务的模块。
其原理是当一个greenlet遇到IO(指的是inputoutput输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
模拟耗时操作:
如果有耗时操作也可以换成,gevent中自己实现的模块,这时候就需要打补丁了。
使用协程完成一个简单的二手房信息的爬虫代码吧!
以下文章来源于Python专栏,作者宋宋
文章链接:
python最大支持多少线程?那啥,python线程太慢了,想并发去用greenlet吧,快,写起来还方便。
如果加锁同步的话,线程多了反而变慢也有可能。
ulimit-s返回线程栈大小,我的默认是8192,用内存大小除以它就得到理论上的线程数吧。
结语:以上就是首席CTO笔记为大家介绍的关于python最多可以多少线程的全部内容了,希望对大家有所帮助,如果你还想了解更多这方面的信息,记得收藏关注本站。
一篇文章带你深度解析Python线程和进程
先检查是否有API
API是网站官方提供的数据接口,如果通过调用API集数据,则相当于在网站允许的范围内集,这样既不会有道德法律风险,也没有网站故意设置的障碍;不过调用API接口的访问则处于网站的控制中,网站可以用来收费,可以用来限制访问上限等。整体来看,如果数据集的需求并不是很独特,那么有API则应优先用调用API的方式。
数据结构分析和数据存储
爬虫需求要十分清晰,具体表现为需要哪些字段,这些字段可以是网页上现有的,也可以是根据网页上现有的字段进一步计算的,这些字段如何构建表,多张表如何连接等。值得一提的是,确定字段环节,不要只看少量的网页,因为单个网页可以缺少别的同类网页的字段,这既有可能是由于网站的问题,也可能是用户行为的差异,只有多观察一些网页才能综合抽象出具有普适性的关键字段——这并不是几分钟看几个网页就可以决定的简单事情,如果遇上了那种臃肿、混乱的网站,可能坑非常多。
对于大规模爬虫,除了本身要集的数据外,其他重要的中间数据(比如页面Id或者url)也建议存储下来,这样可以不必每次重新爬取id。
数据库并没有固定的选择,本质仍是将Python里的数据写到库里,可以选择关系型数据库MySQL等,也可以选择非关系型数据库MongoDB等;对于普通的结构化数据一般存在关系型数据库即可。sqlalchemy是一个成熟好用的数据库连接框架,其引擎可与Pandas配套使用,把数据处理和数据存储连接起来,一气呵成。
数据流分析
对于要批量爬取的网页,往上一层,看它的入口在哪里;这个是根据集范围来确定入口,比如若只想爬一个地区的数据,那从该地区的主页切入即可;但若想爬全国数据,则应更往上一层,从全国的入口切入。一般的网站网页都以树状结构为主,找到切入点作为根节点一层层往里进入即可。
值得注意的一点是,一般网站都不会直接把全量的数据做成列表给你一页页往下翻直到遍历完数据,比如链家上面很清楚地写着有24587套二手房,但是它只给100页,每页30个,如果直接这么切入只能访问3000个,远远低于真实数据量;因此先切片,再整合的数据思维可以获得更大的数据量。显然100页是系统设定,只要超过300个就只显示100页,因此可以通过其他的筛选条件不断细分,只到筛选结果小于等于300页就表示该条件下没有缺漏;最后把各种条件下的筛选结果集合在一起,就能够尽可能地还原真实数据量。
明确了大规模爬虫的数据流动机制,下一步就是针对单个网页进行解析,然后把这个模式复制到整体。对于单个网页,用抓包工具可以查看它的请求方式,是get还是post,有没有提交表单,欲集的数据是写入源代码里还是通过AJAX调用JSON数据。
同样的道理,不能只看一个页面,要观察多个页面,因为批量爬虫要弄清这些大量页面url以及参数的规律,以便可以自动构造;有的网站的url以及关键参数是加密的,这样就悲剧了,不能靠着明显的逻辑直接构造,这种情况下要批量爬虫,要么找到它加密的js代码,在爬虫代码上加入从明文到密码的加密过程;要么用下文所述的模拟浏览器的方式。
数据集
之前用R做爬虫,不要笑,R的确可以做爬虫工作;但在爬虫方面,Python显然优势更明显,受众更广,这得益于其成熟的爬虫框架,以及其他的在计算机系统上更好的性能。scrapy是一个成熟的爬虫框架,直接往里套用就好,比较适合新手学习;requests是一个比原生的urllib包更简洁强大的包,适合作定制化的爬虫功能。requests主要提供一个基本访问功能,把网页的源代码给download下来。一般而言,只要加上跟浏览器同样的Requests Headers参数,就可以正常访问,status_code为200,并成功得到网页源代码;但是也有某些反爬虫较为严格的网站,这么直接访问会被禁止;或者说status为200也不会返回正常的网页源码,而是要求写验证码的js脚本等。
下载到了源码之后,如果数据就在源码中,这种情况是最简单的,这就表示已经成功获取到了数据,剩下的无非就是数据提取、清洗、入库。但若网页上有,然而源代码里没有的,就表示数据写在其他地方,一般而言是通过AJAX异步加载JSON数据,从XHR中找即可找到;如果这样还找不到,那就需要去解析js脚本了。
解析工具
源码下载后,就是解析数据了,常用的有两种方法,一种是用BeautifulSoup对树状HTML进行解析,另一种是通过正则表达式从文本中抽取数据。
BeautifulSoup比较简单,支持Xpath和CSSSelector两种途径,而且像Chrome这类浏览器一般都已经把各个结点的Xpath或者CSSSelector标记好了,直接复制即可。以CSSSelector为例,可以选择tag、id、class等多种方式进行定位选择,如果有id建议选id,因为根据HTML语法,一个id只能绑定一个标签。
正则表达式很强大,但构造起来有点复杂,需要专门去学习。因为下载下来的源码格式就是字符串,所以正则表达式可以大显身手,而且处理速度很快。
对于HTML结构固定,即同样的字段处tag、id和class名称都相同,用BeautifulSoup解析是一种简单高效的方案,但有的网站混乱,同样的数据在不同页面间HTML结构不同,这种情况下BeautifulSoup就不太好使;如果数据本身格式固定,则用正则表达式更方便。比如以下的例子,这两个都是深圳地区某个地方的经度,但一个页面的class是long,一个页面的class是longitude,根据class来选择就没办法同时满足2个,但只要注意到深圳地区的经度都是介于113到114之间的浮点数,就可以通过正则表达式"11[3-4].\d+"来使两个都满足。
数据整理
一般而言,爬下来的原始数据都不是清洁的,所以在入库前要先整理;由于大部分都是字符串,所以主要也就是字符串的处理方式了。
字符串自带的方法可以满足大部分简单的处理需求,比如strip可以去掉首尾不需要的字符或者换行符等,replace可以将指定部分替换成需要的部分,split可以在指定部分分割然后截取一部分。
如果字符串处理的需求太复杂以致常规的字符串处理方法不好解决,那就要请出正则表达式这个大杀器。
Pandas是Python中常用的数据处理模块,虽然作为一个从R转过来的人一直觉得这个模仿R的包实在是太难用了。Pandas不仅可以进行向量化处理、筛选、分组、计算,还能够整合成DataFrame,将集的数据整合成一张表,呈现最终的存储效果。
写入数据库
如果只是中小规模的爬虫,可以把最后的爬虫结果汇合成一张表,最后导出成一张表格以便后续使用;但对于表数量多、单张表容量大的大规模爬虫,再导出成一堆零散的表就不合适了,肯定还是要放在数据库中,既方便存储,也方便进一步整理。
写入数据库有两种方法,一种是通过Pandas的DataFrame自带的to_sql方法,好处是自动建表,对于对表结构没有严格要求的情况下可以用这种方式,不过值得一提的是,如果是多行的DataFrame可以直接插入不加索引,但若只有一行就要加索引否则报错,虽然这个认为不太合理;另一种是利用数据库引擎来执行SQL语句,这种情况下要先自己建表,虽然多了一步,但是表结构完全是自己控制之下。Pandas与SQL都可以用来建表、整理数据,结合起来使用效率更高。
基于python的毕业设计题目(关于python的毕设题目)
使用Python中的线程模块,能够同时运行程序的不同部分,并简化设计。如果你已经入门Python,并且想用线程来提升程序运行速度的话,希望这篇教程会对你有所帮助。
线程与进程
什么是进程
进程是系统进行分配和调度的一个独立单位 进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
什么是线程
CPU调度和分派的基本单位 线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统,只拥有一点在运行中必不可少的(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部。线程间通信主要通过共享内存,上下文切换很快,开销较少,但相比进程不够稳定容易丢失数据。
进程与线程的关系图
线程与进程的区别:
进程
现实生活中,有很多的场景中的事情是同时进行的,比如开车的时候 手和脚共同来驾驶 汽车 ,比如唱歌跳舞也是同时进行的,再比如边吃饭边打电话;试想如果我们吃饭的时候有一个领导来电,我们肯定是立刻就接听了。但是如果你吃完饭再接听或者回电话,很可能会被开除。
注意:
多任务的概念
什么叫 多任务 呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒,这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。 其实就是CPU执行速度太快啦!以至于我们感受不到在轮流调度。
并行与并发
并行(Parallelism)
并行:指两个或两个以上(或线程)在同一时刻发生,是真正意义上的不同或线程在同一时刻,在不同CPU呢上(多核),同时执行。
特点
并发(Concurrency)
指一个物理CPU(也可以多个物理CPU) 在若干道程序(或线程)之间多路复用,并发性是对有限物理强制行使多用户共享以提高效率。
特点
multiprocess.Process模块
process模块是一个创建进程的模块,借助这个模块,就可以完成进程的创建。
语法:Process([group [, target [, name [, args [, kwargs]]]]])
由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)。
注意:1. 必须使用关键字方式来指定参数;2. args指定的为传给target函数的位置参数,是一个元祖形式,必须有逗号。
参数介绍:
group:参数未使用,默认值为None。
target:表示调用对象,即子进程要执行的任务。
args:表示调用的位置参数元祖。
kwargs:表示调用对象的字典。如kwargs = {'name':Jack, 'age':18}。
name:子进程名称。
代码:
除了上面这些开启进程的方法之外,还有一种以继承Process的方式开启进程的方式:
通过上面的研究,我们千方百计实现了程序的异步,让多个任务可以同时在几个进程中并发处理,他们之间的运行没有顺序,一旦开启也不受我们控制。尽管并发编程让我们能更加充分的利用IO,但是也给我们带来了新的问题。
当多个进程使用同一份数据的时候,就会引发数据安全或顺序混乱问题,我们可以考虑加锁,我们以模拟抢票为例,来看看数据安全的重要性。
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改。加锁牺牲了速度,但是却保证了数据的安全。
因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。
mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。队列和管道都是将数据存放于内存中 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性( 后续扩展该内容 )。
线程
Python的threading模块
Python 供了几个用于多线程编程的模块,包括 thread, threading 和 Queue 等。thread 和 threading 模块允许程序员创建和管理线程。thread 模块 供了基本的线程和锁的支持,而 threading 供了更高级别,功能更强的线程管理的功能。Queue 模块允许用户创建一个可以用于多个线程之间 共享数据的队列数据结构。
python创建和执行线程
创建线程代码
1. 创建方法一:
2. 创建方法二:
进程和线程都是实现多任务的一种方式,例如:在同一台计算机上能同时运行多个QQ(进程),一个QQ可以打开多个聊天窗口(线程)。共享:进程不能共享,而线程共享所在进程的地址空间和其他,同时,线程有自己的栈和栈指针。所以在一个进程内的所有线程共享全局变量,但多线程对全局变量的更改会导致变量值得混乱。
代码演示:
得到的结果是:
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行(其中的JPython就没有GIL)。
那么CPython实现中的GIL又是什么呢?GIL全称Global Interpreter Lock为了避免误导,我们还是来看一下官方给出的解释:
主要意思为:
因此,解释器实际上被一个全局解释器锁保护着,它确保任何时候都只有一个Python线程执行。在多线程环境中,Python 虚拟机按以下方式执行:
由于GIL的存在,Python的多线程不能称之为严格的多线程。因为 多线程下每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行。
由于GIL的存在,即使是多线程,事实上同一时刻只能保证一个线程在运行, 既然这样多线程的运行效率不就和单线程一样了吗,那为什么还要使用多线程呢?
由于以前的电脑基本都是单核CPU,多线程和单线程几乎看不出差别,可是由于计算机的迅速发展,现在的电脑几乎都是多核CPU了,最少也是两个核心数的,这时差别就出来了:通过之前的案例我们已经知道,即使在多核CPU中,多线程同一时刻也只有一个线程在运行,这样不仅不能利用多核CPU的优势,反而由于每个线程在多个CPU上是交替执行的,导致在不同CPU上切换时造成的浪费,反而会更慢。即原因是一个进程只存在一把gil锁,当在执行多个线程时,内部会争抢gil锁,这会造成当某一个线程没有抢到锁的时候会让cpu等待,进而不能合理利用多核cpu。
但是在使用多线程抓取网页内容时,遇到IO阻塞时,正在执行的线程会暂时释放GIL锁,这时其它线程会利用这个空隙时间,执行自己的代码,因此多线程抓取比单线程抓取性能要好,所以我们还是要使用多线程的。
GIL对多线程Python程序的影响
程序的性能受到计算密集型(CPU)的程序限制和I/O密集型的程序限制影响,那什么是计算密集型和I/O密集型程序呢?
计算密集型:要进行大量的数值计算,例如进行上亿的数字计算、计算圆周率、对进行解码等等。这种计算密集型任务虽然也可以用多任务完成,但是花费的主要时间在任务切换的时间,此时CPU执行任务的效率比较低。
IO密集型:涉及到网络请求(time.sleep())、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。
当然为了避免GIL对我们程序产生影响,我们也可以使用,线程锁。
Lock&RLock
常用的共享锁机制:有Lock、RLock、Semphore、Condition等,简单给大家分享下Lock和RLock。
Lock
特点就是执行速度慢,但是保证了数据的安全性
RLock
使用锁代码操作不当就会产生死锁的情况。
什么是死锁
死锁:当线程A持有独占锁a,并尝试去获取独占锁b的同时,线程B持有独占锁b,并尝试获取独占锁a的情况下,就会发生AB两个线程由于互相持有对方需要的锁,而发生的阻塞现象,我们称为死锁。即死锁是指多个进程因竞争而造成的一种僵局,若无外力作用,这些进程都将无法向前推进。
所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定的合理分配算法,避免进程永久占据系统。
死锁代码
python线程间通信
如果各个线程之间各干各的,确实不需要通信,这样的代码也十分的简单。但这一般是不可能的,至少线程要和主线程进行通信,不然计算结果等内容无法取回。而实际情况中要复杂的多,多个线程间需要交换数据,才能得到正确的执行结果。
python中Queue是消息队列,提供线程间通信机制,python3中重名为为queue,queue模块块下提供了几个阻塞队列,这些队列主要用于实现线程通信。
在 queue 模块下主要提供了三个类,分别代表三种队列,它们的主要区别就在于进队列、出队列的不同。
简单代码演示
此时代码会阻塞,因为queue中内容已满,此时可以在第四个queue.put('苹果')后面添加timeout,则成为 queue.put('苹果',timeout=1)如果等待1秒钟仍然是满的就会抛出异常,可以捕获异常。
同理如果队列是空的,无法获取到内容默认也会阻塞,如果不阻塞可以使用queue.get_nowait()。
在掌握了 Queue 阻塞队列的特性之后,在下面程序中就可以利用 Queue 来实现线程通信了。
下面演示一个生产者和一个消费者,当然都可以多个
使用queue模块,可在线程间进行通信,并保证了线程安全。
协程
协程,又称微线程,纤程。英文名Coroutine。
协程是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的)。为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机, 我们可以把一个协程 切换到另一个协程。只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定。
在实现多任务时,线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
greenlet与gevent
为了更好使用协程来完成多任务,除了使用原生的yield完成模拟协程的工作,其实python还有的greenlet模块和gevent模块,使实现协程变的更加简单高效。
greenlet虽说实现了协程,但需要我们手工切换,太麻烦了,gevent是比greenlet更强大的并且能够自动切换任务的模块。
其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
模拟耗时操作:
如果有耗时操作也可以换成,gevent中自己实现的模块,这时候就需要打补丁了。
使用协程完成一个简单的二手房信息的爬虫代码吧!
以下文章来源于Python专栏 ,作者宋宋
文章链接:s://mp.weixin.qq/s/2r3_ipU3HjdA5VnqSHjUnQ
基于python的毕业设计题目是什么?
如下:
1基于MapReduce的气候数据的分析
2基于关键词的文本知识的挖掘系统的设计与实现
3基于概率图模型的蛋白质功能预测
4基于第三方库的人脸识别系统的设计与实现
5基于hbase搜索引擎的设计与实现
6基于Spark-Streaming的黑名单实时过滤系统的设计与实现
7客户潜在价值评估系统的设计与实现
8基于神经网络的文本分类的设计与实现
9基于Apriori的商品关联关系分析与挖掘
10基于词频统计的中文分词系统的设计与实现
11K-means算法在微博数据挖掘中的应用
12图像对象检测分析系统的研究和应用
13基于Apriori关联规则的电子商务潜在客户的数据挖掘
14基于Spark的电商用户行为分析系统的设计与实现
15音乐推荐系统的研究与应用
16基于大数据的高校网络舆情监控引导系统的研究与应用
17基于医疗大数据的肿瘤疾病模式分析与研究
18基于支持向量机的空间数据挖掘及其在旅游地理经济中的应用
19基于深度残差网络的糖尿病视网膜病变分类检测研究
20基于大数据分析的门户信息推荐系统
21Web数据挖掘及其在电子商务中的研究与应用
基于python的毕业设计题目难吗不难。基于python的毕业设计题目是带教老师给定的,只要平时认真完成了老师布置的作品,是不难的。题目是指考试或练习时要求应试人作答的问题或指文章或诗篇的标名。
计算机毕业论文题目推荐计算机毕业论文题目推荐如下:基于SpringBoot的个性化学习系统设计与实现。基于web的疫情期间物资分配管理系统的设计与实现。基于python的成都市二手房数据可视化系统的设计基于SpringBoot的电子秤串口称重系统的设计与实现基于Ja的疫情防控服务平台的设计与实现基于Web的开源协会服务平台的设计与实现基于ssm的汽车租赁平台的设计与开发
基于Ja的同城临期平台的设计与开发。基于SpringBoot的协同过滤就业系统的设计与实现。基于SpringMVC的互联网招聘求职网站的设计与实现。基于SrpingBoot+react的登记分享网站的设计与实现。基于Springboot的在线教育平台设计与实现。基于Springboot的货物管理系统的设计与实现
基于Springboot的医疗管理系统的设计与实现。基于Springboot的校园快递管理平台的设计与实现。基于Springboot的博课系统的设计与实现。基于web应用的互助型旅游网站系统开发基于SpringBoot的沉浸式学习系统设计与实现。基于Springboot的预约挂号系统的设计与实现。基于python的疫情数据分析系统的设计与开发。
用Python做毕业设计选什么项目比较好?python毕业设计Django框架实现学生信息管理系统
自学的python基础
然后学习Django框架
改改乱七八糟的东西
做出来了个简单的....毕业设计
将所在学院的信息以csv格式上传数据库然后前后端调用
实现了学生信息管理系统
改写了Django框架中的admin
用的xadmin优化了页面
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。